Semi-Blindly Enhancing Extremely Noisy Videos With Recurrent Spatio-Temporal Large-Span Network
IEEE Transactions on Pattern Analysis and Machine Intelligence 2023
DG20230004@smail.nju.edu.cn, xuemeihu@nju.edu.cn, yuetao@nju.edu.cn
|
Semi-Blindly Enhancing Extremely Noisy Videos With Recurrent Spatio-Temporal Large-Span Network IEEE Transactions on Pattern Analysis and Machine Intelligence 2023 DG20230004@smail.nju.edu.cn, xuemeihu@nju.edu.cn, yuetao@nju.edu.cn
|
|
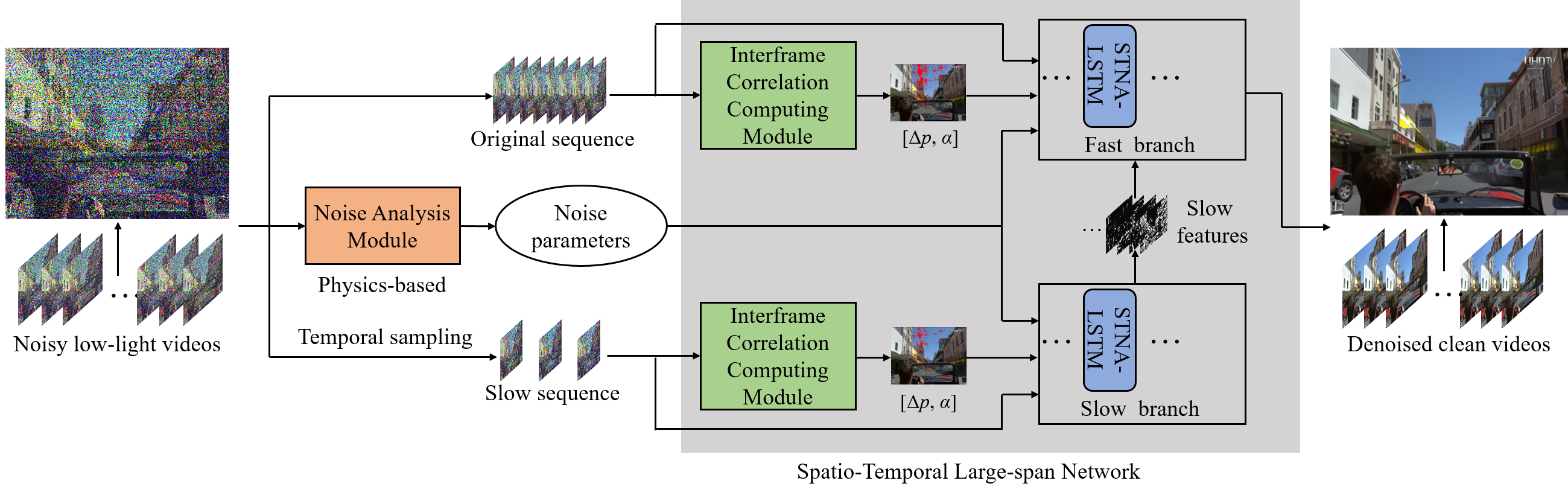
Abstract Capturing videos under the extremely dark environment is quite challenging for the extremely large and complex noise. To accurately represent the complex noise distribution, the physics-based noise modeling and learning-based blind noise modeling methods are proposed. However, these methods suffer from either the requirement of complex calibration procedure or performance degradation in practice. In this paper, we propose a semi-blind noise modeling and enhancing method, which incorporates the physics-based noise model with a learning-based Noise Analysis Module (NAM). With NAM, self-calibration of model parameters can be realized, which enables the denoising process to be adaptive to various noise distributions of either different cameras or camera settings. Besides, we develop a recurrent Spatio-Temporal Large-span Network (STLNet), constructed with a Slow-Fast Dual-branch (SFDB) architecture and an Interframe Non-local Correlation Guidance (INCG) mechanism, to fully investigate the spatio-temporal correlation in a large span. The effectiveness and superiority of the proposed method are demonstrated with extensive experiments, both qualitatively and quantitatively. |
|
Method Noise Model Most video denoising or enhancing algorithms assume that the noise follows a simple assumption, e.g., i.i.d. AWGN, Poisson or mixture noises, etc. However, for the extremely low-light conditions, some noise components become dominant, leading to a tremendous change in the noise distribution, in which case, these simple assumptions are inadequate. For example, for the picture captured in the low-light environment (approximately 0.01 Lux) by Canon 5D MarkIII with ISO 25600, and the synthesized deteriorated result from a corresponding clear image with i.i.d. AWGN of equal noise variance, their noise distributions are obviously different, manifesting as dynamic streak noise (DSN), color heterogenous, and clipping effect. Aiming at making up this gap between synthesis and reality, we propose a physics-based noise model considering all these practical effects and a NAM to automatically estimate parameters of the proposed noise model from noisy images. Based on the proposed physics-based noise model and NAM, we can simulate the practical noise more accurately. 
Denoising Network The STLNet is designed with the SFDB architecture and INCG mechanism, to fully utilize the spatio-temporal large span information recurrently. The SFDB architecture contains two branches, i.e., the slow and fast branches, to process sequences with different framerates. Information fusion between the fast and slow branches is introduced every four frames, alleviating the vanishing gradient problem of LSTM-based networks when handling long videos. The INCG mechanism is designed to comprehensively investigate the non-local information. Specifically, the INCG mechanism is composed of ICCM and STNA-LSTM. The ICCM receives two input frames, i.e., the reference frame and the neighbor frame, and extracts the interframe correlations. The interframe correlations are then fed to STNA-LSTMs to guide the transmission of the interframe non-local information, increasing the spatial span of information aggregation. Furthermore, incorporated with the recurrent mechanism of LSTM, the proposed INCG mechanism can further expand the spatial span of correlated pixels. 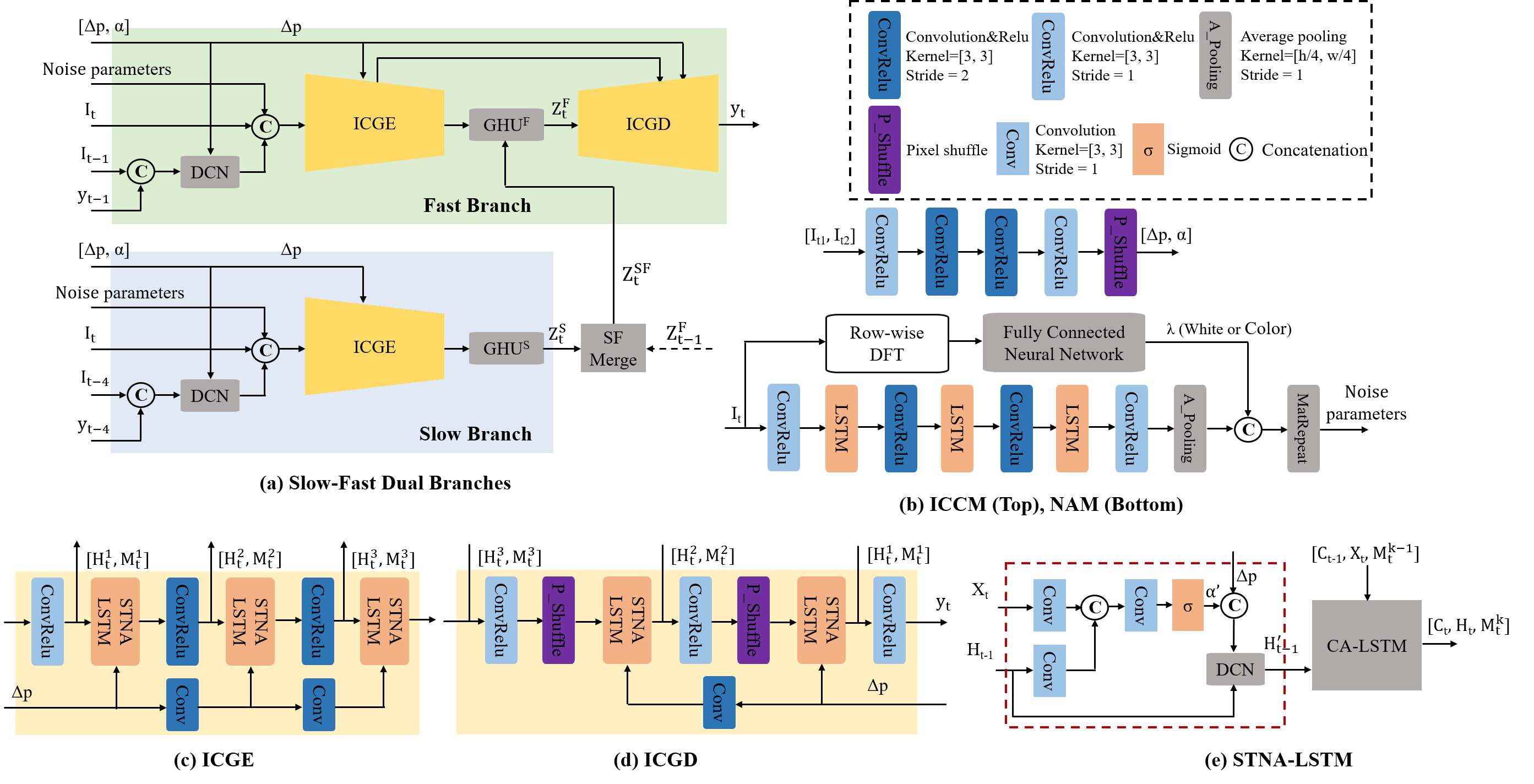
Dataset We collect about 3,000 clean video sequences online as the label of training data, including human sports, natural scenarios, streetscapes, architectures, animals, etc. Each sequence is composed of 24 images of the same scene. To generate the noisy data, we calibrate the noise parameters of four typical cameras manually, including a consumer-level singlelens reflective camera (Canon 5D MarkIII), a mirrorless camera (Sony a7s3), a high-performance low-light camera (ASI294MC Pro) and a widely used industrial camera (Grasshopper3 GS3-U3-32S4C). Based on these references, we approximately set the possible range of the noise model parameters. The expected photoelectron number is set from dark to normal illumination, considering all the possible illumination conditions of the practical low-light capture environments. A large number of possible parameter groups within the range are generated randomly and used to produce noisy videos from clean videos through the Monte Carlo method. With the proposed method of dataset generation, the dataset can well represent various practical noise distributions of different camera types or settings. Both the pretraining of NAM and the training of the whole network adopt this training data generation method. As for testing, we collect another 136 videos longer than 50 frames with various scenes, e.g., ocean, animals, plants, people, cities, interiors, and cars, for generating the testing dataset. Four groups of parameters corresponding to four typical cameras, i.e., Canon 5D MarkIII, Sony a7s3, ASI294MC Pro and Grasshopper3 GS3-U3-32S4C, are used to generate the four groups of testing data. Besides, an additional group with randomly sampled noise parameters is also applied for testing. In this group, the noise parameters of each video are sampled from the possible parameter range of the noise model. In addition, the randomly sampled noise parameters in the testing dataset are checked to filter out samples appeared in the training dataset, ensuring the credibility of the experiments. 
|
|
Experiments Evaluation on the Synthesized Data We test the proposed method on the synthetic data generated with the proposed noise model and compare it with other state-of-the-art algorithms. For a fair comparison, parameters of VBM4D are chosen carefully for the best performance, and the learning-based methods are retrained with the same training dataset and training strategies provided in their original papers. The proposed method performs the best in both SSIM and PSNR, followed by Base. As a recurrent-based network, Base combines the CA-LSTM and alternative gradient highway, promisingly exploiting the spatial correlations and long-shortterm information. Benefiting from the NAM and the STLNet in this paper, the proposed method achieves much better performance than Base. Considering the reconstruction quality of local details, the proposed method shows more elegant performance, e.g., the window of the building, the hair of the man, the pink flowers and the tree canopy in the bus scene, the eye, and the texture on the sleeve in the baby scene.  Evaluation on Real Captured Videos We demonstrate the denoising results of four scenes captured with Canon 5D MarkIII (rolling shutter) and Grasshopper3 GS3-U3-32S4C camera (global shutter). As shown, more details, e.g., the patterns on the little car toy, the alphabets on the boards, and the clocks, could be recovered with much higher visual quality with the proposed method. Furthermore, nearly no color distortion is introduced by the proposed method, which can be obviously observed in the other methods in the results of Canon 5D MarkIII, mainly due to the incompetence in dealing with the DSN. Note that, benefiting from the dualbranch structure that could handle the high-frequency information individually, RSDN outperforms Base in detail reconstruction but performs worse on flat areas. The proposed method achieves better performance on both detailed and flat regions, from an overall pespective. 
|
|
More Details
|
|
Bibtex @article{10005850, title={Semi-Blindly Enhancing Extremely Noisy Videos With Recurrent Spatio-Temporal Large-Span Network}, author={Chen, Xin and Hu, Xuemei and Yue, Tao}, journal={IEEE Transactions on Pattern Analysis and Machine Intelligence}, year={2023}, volume={45}, pages={8984-9003}, doi={10.1109/TPAMI.2023.3234026} } |